Preliminary Results
Barnes-Hut is a high-communication problem, so we do not expect linear speedup from either the single-node MPI implementation or the distributed MMPI implementation. Both implementations ran a simulation of 50,000 stars on GHC machines only. A serial implementation takes around 100ms per iteration.
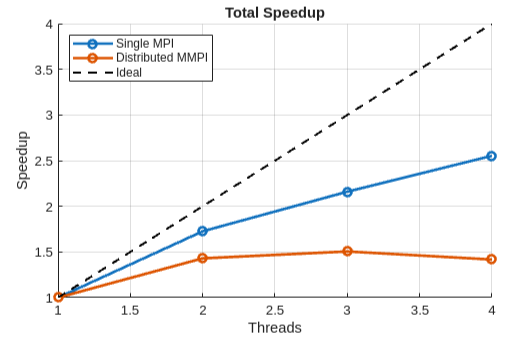
Despite the subpar interconnect between separate GHC machines for the distributed implementation, we were surprised to see that it still had potential for speedup, reaching nearly 1.5x on 2 nodes (though single-node MPI reaches 1.7x). Although adding more nodes beyond 2 does not improve speedup, we believe that this is due to our currently naive implementation of allgather, which sends all data to a single node and broadcasts back to everyone else.